
はじめに
ROC(Receiver Operating Characteristic)曲線とAUC(Area Under the Curve)は、機械学習や統計分析において、分類モデルの評価と比較に広く使用される重要な指標です。この記事では、ROC曲線とAUCの基本的な概念とその有用性について解説します。
ROC曲線やAUCは分類モデルの評価で多くの場面で活用されます。しかしAUCの概念はやや複雑で分かりにくいため、経験豊富な方とマンツーマンで学習していくのもオススメです。
分類予測とは
分類予測は、機械学習の一分野であり、与えられたデータを複数のカテゴリやクラスに分類するためのモデルの構築を指します。この手法は、事前に与えられたトレーニングデータから学習し、未知のデータに対して予測を行います。具体的なアプリケーションとしては、手書き文字認識やスパムメールの検出が挙げられます。
ROC曲線を学ぶ前に
ここでは、「病気の検査結果」を例に、これらの指標に用いられる語句を説明します。例えば、ある病気の検査結果を陽性(1)と陰性(0)に分類する問題を考えます。
次のテーブルは、モデルの予測結果を整理したものです。予測と実際が同じかどうかという点において、それぞれの区域で名前が付けられています。
| 予測結果/実際 | 予測: 陽性 | 予測: 陰性 |
| 実際: 陽性 (Positive) | True Positive (TP) | False Negative (FN) |
| 実際: 陰性 (Negative) | False Positive (FP) | True Negative (TN) |
- True Positive (TP): モデルが「陽性」と予測し、実際にも病気があった人数。これは、正しく分類された陽性結果の数を意味します。
- False Positive (FP): モデルが「陽性」と予測したが、実際には病気がなかった人数。これは、陽性と誤分類された陰性結果の数を意味します。
- False Negative (FN): モデルが「陰性」と予測したが、実際には病気があった人数。これは、陰性と誤分類された陽性結果の数を意味します。
- True Negative (TN): モデルが「陰性」と予測し、実際にも病気がなかった人数。これは、正しく分類された陰性結果の数を意味します。
ROC曲線とは
ROC曲線は、分類モデルの真陽性率(TPR)と偽陽性率(FPR)の関係を表現するグラフです。
- 真陽性率(TPR):真陽性率は、実際に陽性であるデータのうち、モデルが正しく陽性と予測した割合を示します。
- 偽陽性率(FPR):偽陽性率は、実際には陰性であるデータのうち、モデルが誤って陽性と予測した割合を示します。
ROC曲線は、これらの指標を異なる閾値で計算し、その結果をグラフにプロットすることで、モデルの性能を視覚的に評価します。
実際のROC曲線は下記のオレンジ線になりますが、縦軸にTPR、横軸にFPRを配置します。
ROC曲線の作成方法
ROC曲線を作成するためには、分類モデルの予測確率と真のラベルを使用します。
まず、予測確率に基づいてデータを降順にソートします。次に、最初の閾値を設定し、予測確率が閾値以上のサンプルを正例と分類し、閾値未満のサンプルを負例と分類します。その後、TPRとFPRを計算し、結果をプロットします。閾値を変えながら同じ手順を繰り返し、ROC曲線全体を描画します。
閾値を変化させた具体的な例
予測データ
下記の予測データを用いていきます。
| サンプルID | 真のラベル | 予測確率(ソート後) |
| 1 | 陽性 | 0.95 |
| 2 | 陰性 | 0.80 |
| 3 | 陽性 | 0.70 |
| 4 | 陰性 | 0.60 |
| 5 | 陽性 | 0.55 |
| 6 | 陰性 | 0.30 |
予測データ 閾値0.6
閾値0.6とし、それ以上と未満を下記とします。
- 0.6以上を陽性と予測
- 0.6未満を陰性と予測
| サンプルID | 真のラベル | 予測確率(ソート後) | 予測結果 | 結果 |
| 1 | 陽性 | 0.95 | 陽性 | 真陽性 |
| 2 | 陰性 | 0.80 | 陽性 | 偽陽性 |
| 3 | 陽性 | 0.70 | 陽性 | 真陽性 |
| 4 | 陰性 | 0.60 | 陽性 | 偽陽性 |
| 5 | 陽性 | 0.55 (閾値未満) | 陰性 (閾値未満のため陰性) | 偽陰性 |
| 6 | 陰性 | 0.30 (閾値未満) | 陰性 (閾値未満のため陰性) | 真陰性 |
上記の結果を混同行列に入れていき、TPRとFPRを算出します。
| 予測結果/実際 | 予測: 陽性 | 予測: 陰性 |
| 実際: 陽性 (Positive) | True Positive (TP) :2 | False Negative (FN):1 |
| 実際: 陰性 (Negative) | False Positive (FP):2 | True Negative (TN):1 |
予測データ 閾値0.4
閾値0.4とし、それ以上と未満を下記とします。
- 0.4以上を陽性と予測
- 0.4未満を陰性と予測
| サンプルID | 真のラベル | 予測確率(ソート後) | 予測結果 | 結果 |
| 1 | 陽性 | 0.95 | 陽性 | 真陽性 |
| 2 | 陰性 | 0.80 | 陽性 | 偽陽性 |
| 3 | 陽性 | 0.70 | 陽性 | 真陽性 |
| 4 | 陰性 | 0.60 | 陽性 | 偽陽性 |
| 5 | 陽性 | 0.55 | 陽性 | 真陽性 |
| 6 | 陰性 | 0.30 (閾値未満) | 陰性 (閾値未満のため陰性) | 真陰性 |
再度上記の結果を混同行列に入れていき、TPRとFPRを算出します。
| 予測結果/実際 | 予測: 陽性 | 予測: 陰性 |
| 実際: 陽性 (Positive) | True Positive (TP) :3 | False Negative (FN):0 |
| 実際: 陰性 (Negative) | False Positive (FP):2 | True Negative (TN):1 |
AUCの算出方法
以上のように閾値を変更していくとTPRおよびFPRが変化していきます。その変化を二次元のグラフ表したものがROC曲線となります。
オープンデータを使って実際に予測し、ROC曲線を作っていきます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve, auc
# データセットの読み込み
data = load_breast_cancer()
X = data.data
y = data.target
# データセットをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# RandomForestClassifierモデルの学習
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# テストセットでの予測確率を取得
y_score = model.predict_proba(X_test)[:, 1]
# ROC曲線を計算
fpr, tpr, thresholds = roc_curve(y_test, y_score)
roc_auc = auc(fpr, tpr)
# ROC曲線をプロット
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.3f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='Random guess')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.grid(True)
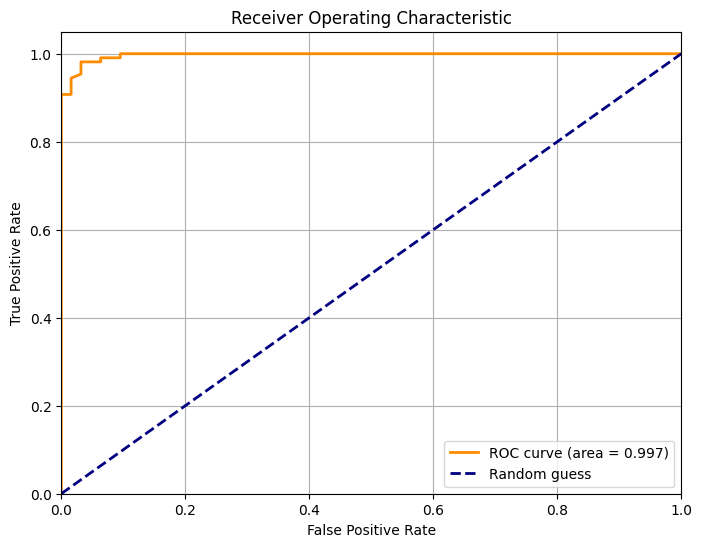
plt.show()x軸がFPR、y軸がTPRとし、先ほどのように閾値を変化させていくと、オレンジ線のようにROC曲線と呼ばれるFPR、TPRがプロットされていきます。
AUCはROC曲線の下の面積を表す指標です。AUCの値は、分類モデルの性能を定量化するために使用されます。AUCの範囲は0から1の間であり、1に近いほど優れたモデル性能を示します。完全な分類能力を持つモデルはAUCが1となります。今回の場合はAUC = 0.997となり、非常に高い精度を示しました。
AUCの解釈
AUCは、分類モデルの性能を簡潔に評価するための重要な指標です。
- 優れた分類能力の指標: AUCが高いモデルは、高い真陽性率(TPR)と低い偽陽性率(FPR)を持ちます。AUCが1に近いほど、モデルの分類能力が高いと言えます。
- クラスの不均衡なデータに対する頑健性: クラスの不均衡がある場合でも、AUCは優れた性能評価指標です。AUCは、偽陽性率を含む全ての閾値にわたるモデルの性能を統合的に評価するため、クラスの不均衡なデータセットにおいても妥当な評価ができます。
まとめ
ROC曲線とAUCは、分類モデルの評価と比較において重要なツールです。ROC曲線は、分類器の真陽性率と偽陽性率の関係を視覚化し、モデルの性能を可視化します。AUCは、ROC曲線の下の面積を示し、分類モデルの性能を定量化します。高いAUC値は優れたモデル性能を示し、クラスの不均衡なデータに対しても頑健な評価指標です。機械学習や統計分析の分野でROC曲線とAUCを適切に理解し活用することは、モデルの性能向上につながるでしょう。
評価指標の学習にオススメの方法
書籍:評価指標入門〜データサイエンスとビジネスをつなぐ架け橋
こちらの書籍は様々な評価指標をまとめており、分類問題だけでなく、回帰問題での評価指標の学習にもおススメです。こちらを学習することで適正な指標をビジネスに活用できるようになりましょう。

スクール:現役データサイエンティストに教えてもらう
機械学習の正しい評価を実施することでビジネスを正しい方向に進めることができます。ただ、AUCなど、やや複雑な手法を正しく理解するためにはスクールなどでアドバイスしてもらいながら進めるのも良いでしょう。



コメント