
はじめに
機械学習の世界では、様々なアルゴリズムが開発されていますが、その中でも高い予測精度と安定性でよく使われているのが「ランダムフォレスト」です。
本記事では、ランダムフォレストの基本概念から、Pythonを使った実装まで解説します。
しかし、もしこれらについて理解が難しい場合は、経験豊富な方とマンツーマンで学習していくのもオススメです。
ランダムフォレストとは
ランダムフォレスト(Random Forest)は、複数の決定木(Decision Tree)を組み合わせたアンサンブル学習手法です。
「ランダム」という名が示す通り、ランダム性を活用することで単一の決定木よりも高い精度と汎化性能を実現しています。
ランダムフォレストは次のプロセスで学習・予測を行います。
- 訓練データからランダムサンプリング(ブートストラップサンプリング)で複数のサブセットを作成
- 各サブセットに対して決定木を構築(特徴量もランダムに選択)
- 全ての決定木の予測結果を集約(分類問題では多数決、回帰問題では平均)
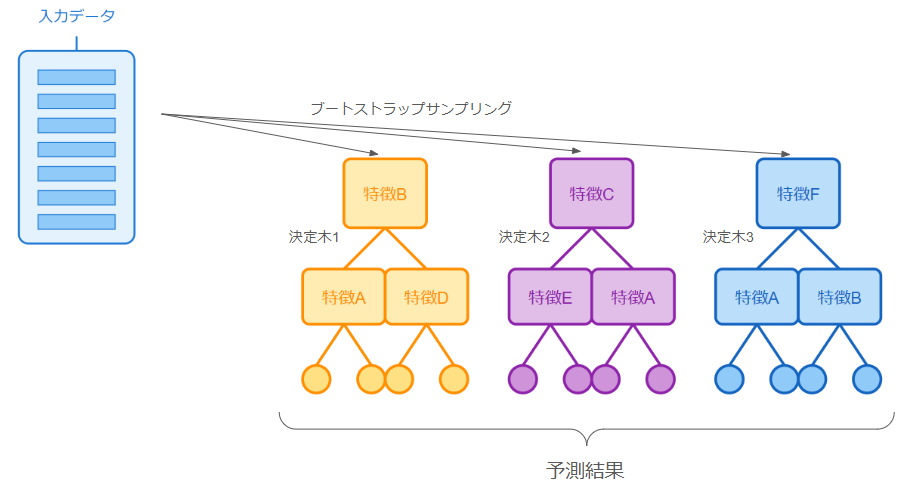
このように多くの決定木の結果を用いて予測することから、過学習に強い高精度なモデルを作成できます。
ランダムフォレストの特徴
- 高い予測精度:多数の決定木の「多数決」で予測するため、単一モデルよりも高精度
- 過学習に強い:ランダム性により、訓練データに特化しすぎることを防止
- 特徴量の重要度評価:各特徴量の重要度を評価できる機能を内蔵
- 外れ値に強い:複数モデルの組み合わせで外れ値の影響を軽減
Pythonでランダムフォレストを実装する
それでは、Pythonを使ってランダムフォレストを実装してみましょう。ここではscikit-learnというライブラリを使います。
必要なライブラリのインポート
まずは用いるライブラリをインポートします。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.datasets import load_irisデータの準備
今回はscikit-learnに組み込まれているアヤメのデータセット(Iris dataset)を使います。
# アヤメのデータセットを読み込む
iris = load_iris()
X = iris.data
y = iris.target
# データを訓練用とテスト用に分割(70%:30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)ランダムフォレストモデルの構築と学習
ランダムフォレストを用いて学習します。
# ランダムフォレストのインスタンスを作成(100本の決定木を使用)
rf_model = RandomForestClassifier(n_estimators=100, random_state=0)
# モデルを訓練データで学習
rf_model.fit(X_train, y_train)モデルの評価
testデータを用いて、予測精度を確認していきます。0.9778と出ました。
# テストデータで予測
y_pred = rf_model.predict(X_test)
# 精度を評価
accuracy = accuracy_score(y_test, y_pred)
print(f"精度: {accuracy:.4f}")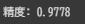
特徴量の重要度を可視化
ランダムフォレストの便利な機能として、各特徴量の重要度を評価できます。
# 特徴量の重要度を取得
feature_importances = rf_model.feature_importances_
# 特徴量の名前とその重要度を対応付ける
feature_importance_dict = dict(zip(iris.feature_names, feature_importances))
# 重要度の降順にソート
sorted_features = sorted(feature_importance_dict.items(), key=lambda x: x[1], reverse=True)
# 可視化
plt.figure(figsize=(10, 6))
plt.bar(range(len(feature_importances)), [imp for _, imp in sorted_features])
plt.xticks(range(len(feature_importances)), [name for name, _ in sorted_features], rotation=45)
plt.title('ランダムフォレストにおける特徴量の重要度')
plt.tight_layout()
plt.show()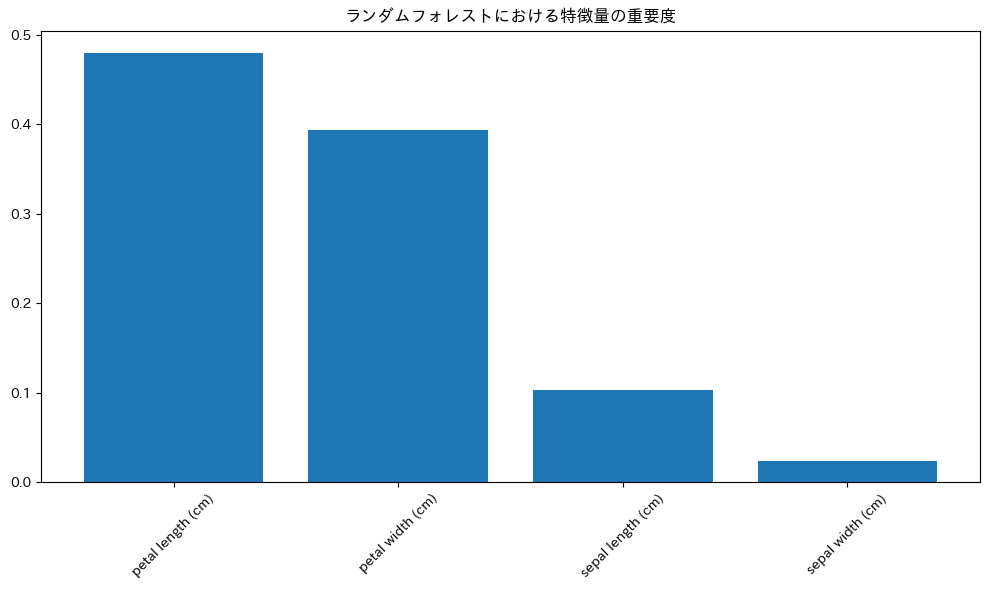
まとめ
ランダムフォレストは、その高い予測精度と使いやすさから、機械学習の現場で広く利用されているアルゴリズムです。
特に初心者にも扱いやすく、チューニングせずとも高いパフォーマンスを発揮することが多いため、機械学習プロジェクトの第一選択肢として最適です。
今回紹介したPython実装例を参考に、ぜひ自分のデータでランダムフォレストを試してみてください。
ランダムフォレストを学ぶのにオススメの方法
書籍:機械学習図鑑
下記の書籍は初学者向けに様々な機械学習が視覚的に描かれています。ランダムフォレストをはじめ、様々な分析について視覚的に理解していきたい方にはオススメです。

スクール:現役データサイエンティストに教えてもらう
ランダムフォレストはデータ分析で良く用いられますが、高精度を出すことができます。一方で導入の際にはビジネス側に説明をすることがあるため、しっかりと理解することが重要です。
スクールなどに入り、アドバイスしてもらいながら理解して進めるのも良いでしょう。



コメント