
はじめに
ディープラーニングにおいて、モデルの学習を進めるために最適なパラメータを見つけるための重要な要素が最適化関数です。最適化関数の選択は、モデルの収束速度、学習の安定性、性能の最適化に直接的な影響を与える重要な決定です。本記事では、最適化関数の役割、一般的な最適化関数の紹介、および最適化関数を選択する際のポイントについて解説していきます。
最適化関数は、深層学習を用いる際に非常に重要な知識となりますが、これらについて理解が難しい場合は、経験豊富な方とマンツーマンで学習していくのもオススメです。
最適化関数の役割
最適化関数は、モデルのパラメータを更新することで、訓練データに対する損失を最小化する役割を果たします。具体的には、勾配(損失関数の微分)を使用してパラメータの更新を行います。また、学習率の調整も最適化関数が担当し、効率的な学習を実現します。
具体的には以下のようなイメージで、モデルを予測した後、予測と実測の差(エラー)を計算します。その時の予測パラメータを調整することでエラーを少なくしていきます。その際にパラメータをどう調整していくかを決めるのが最適化関数です。
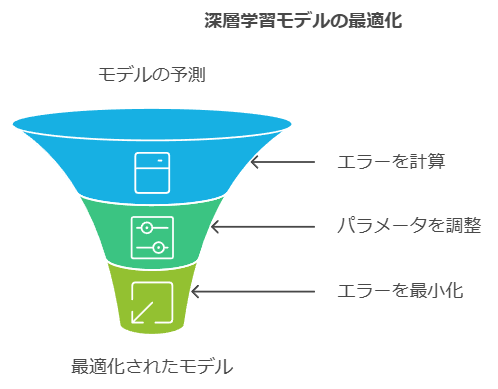
一般的な最適化関数
以下は一部の一般的な最適化関数の紹介です。
- 勾配降下法(Gradient Descent):基本的な最適化アルゴリズムであり、勾配を利用してパラメータの更新を行います。
- 確率的勾配降下法(Stochastic Gradient Descent, SGD):ミニバッチを使用してパラメータの更新を行う勾配降下法の一種です。
- モーメンタム(Momentum):過去の勾配の情報を使用して収束速度を向上させる手法です。
- アダム(Adam):モーメンタムと学習率の調整を組み合わせた最適化手法であり、高い収束速度とパラメータの最適化を実現します。
- RMSprop(Root Mean Square Propagation):過去の勾配の二乗平均の情報を使用して学習率を調整する最適化手法です。
最適化関数選択のポイント
最適化関数を選択する際のポイントは以下の通りです。
- 問題やデータセットの特性に応じた選択:最適化関数は問題やデータセットに依存して選択されるべきです。例えば、大規模なデータセットではSGDやミニバッチ勾配降下法(Mini-batch Gradient Descent)が効果的です。また、非線形な関数を学習する場合には、モーメンタムやアダムなどのより洗練された最適化関数が良い結果をもたらすことがあります。
- ハイパーパラメータの調整:最適化関数にはハイパーパラメータがあります。例えば、学習率やモーメンタムの係数などです。適切なハイパーパラメータの設定は、最適化関数の性能に大きな影響を与えます。クロスバリデーションやハイパーパラメータの最適化手法を使用して、最適な設定を見つけることが重要です。
- 実験と評価:最適化関数の選択は、試行錯誤と実験を通じて行うべきです。異なる最適化関数を使ってモデルをトレーニングし、性能や収束速度を比較して評価します。また、クロスバリデーションやテストセットでの性能評価も重要です。これにより、最適な最適化関数を見つけることができます。
まとめ
最適化関数は、ディープラーニングにおいてモデルの学習を進めるための重要な要素です。最適な最適化関数の選択は、モデルの収束速度や学習の安定性、性能の最適化に直接的な影響を与えます。適切な最適化関数の選択とハイパーパラメータの調整により、モデルの性能を向上させることができます。
しかし、最適化関数の選択は問題やデータセットに依存し、最適化関数単体では結果が決まるわけではありません。試行錯誤を通じて最適な最適化関数を見つけ、実験と評価を重ねることが重要です。
深層学習におすすめの書籍
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
こちらの書籍は深層学習の基本が網羅的にまとめられており、基本を身に着けるのにおススメです。深層学習は応用先も多いため、基礎をこちらの書籍で学ぶことをおススメします。



コメント