
はじめに
深層学習は、機械学習の分野において多くビジネスにも活用されています。その中でも、ニューラルネットワークの訓練において重要な役割を果たすのが「学習率」です。
本記事では、深層学習においてどのように学習率が利用されているか、その役割や調整方法に焦点を当てて解説します。
複雑で理解が難しいですが、これらについて理解が難しい場合は、経験豊富な方とマンツーマンで学習していくのもオススメです。
深層学習の学習率とは
深層学習は、パラメータの最適な値を見つけるために学習アルゴリズムを使用します。学習アルゴリズムの中でも重要な要素の一つが学習率です。
学習率は、「各パラメータの更新時にどれだけのステップを進めるかを制御するパラメータ」となります。
下記の通りでパラメータを更新し、損失を減らしていきます。

学習率は、モデルの学習の速度や精度に影響を与えるため、適切な値を選ぶことが非常に重要です。
学習率が小さすぎると、モデルの収束に時間がかかり、最適解に到達するまでに多くのエポックが必要になる可能性があります。
一方、学習率が大きすぎると、最適解を見逃す可能性があり、モデルが発散してしまうこともあります。
学習率に用いられる損失関数とパラメータとは
学習率の理解には損失関数とパラメータの理解が必要になります。
損失関数とは
損失関数\( L \)(Loss Function)は、モデルの予測値と真の値との「差」を数値化した関数です。
深層学習の目標は、この損失関数を最小化することです。
一般的に下記のものが使われることが多いです。
- 2乗和誤差:\( L = \frac{1}{2} \sum_{k} (y_k – t_k)^2 \)
- 交差エントロピー誤差:\( L = – \sum_{k} t_k \log({y_k}) \)
ここで\( y_k \)は予測値、\( t_k \)は実績値です。
これらの誤差をパラメータを変化させた時に最小化させていきます。
パラメータとは
深層学習を行う際、次のニューロンに行く際に重み\( w \)が掛け合わされて、次に進みます。
今回はこの\( w \)をパラメータと呼び、これを最適化することで\( L \)を最小化させます。
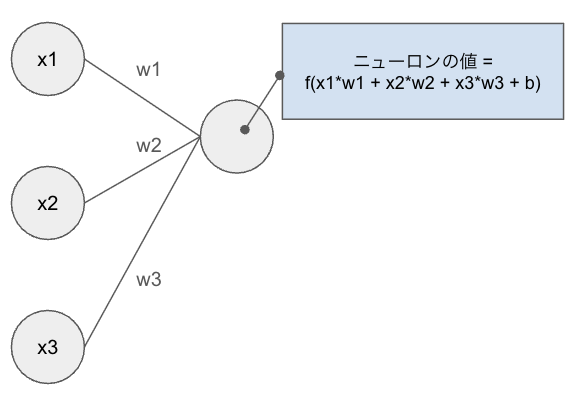

パラメータの更新と損失関数の最小化
パラメータを更新させていくことで、損失関数を最小化させていきます。
その際に、用いる式がこちらとなります。\( \eta \)が学習率です。
\( w \)で偏微分した値をマイナスしていき更新をかけます。
下記の通り、損失関数が2乗の形の場合はどこにパラメータがあったとしても最小方向に更新されていきます。
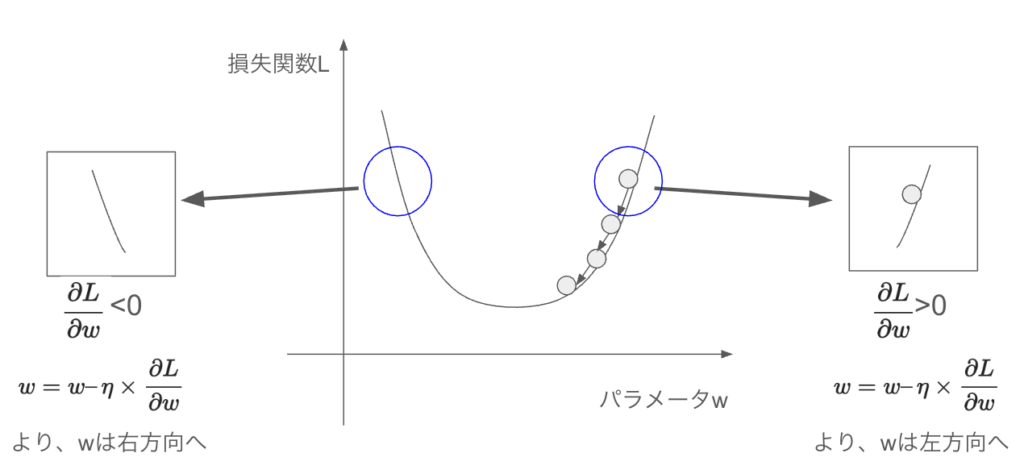
この更新の大きさを決めるのが「学習率 \( \eta \)」です。
学習率が大きい場合はパラメータの更新量も大きくなるということに注意が必要です。
深層学習における学習率のパラメータ調整
深層学習の学習率を調整する際、学習率が大きすぎると損失関数が最小のポイントにたどりつかないことがあります。
そのため、いくつかの学習率を試した上で、アウトプットを確認していきましょう。
まとめ
深層学習において、学習率はモデルの訓練における鍵となります。正確な調整がモデルの収束性や訓練速度に直結し、最終的な性能向上に寄与します。
適切な学習率を見つけるためには手動調整や自動調整の手法を巧みに組み合わせ、最新の最適化手法を取り入れることが重要です。
学習率を詳しく学びたい方にオススメの方法
書籍:ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
深層学習を学ぶと言ったらこの本、というほど分かりやすい初心者向けの書籍となります。学習率の意味や使い方を理解するためにはオススメの一冊です。

スクール:現役データサイエンティストに教えてもらう
ディープラーニングを構成する技術は様々な場面で活用されるため、網羅的に学習することがオススメです。
難しい場合はスクールなどに入り、アドバイスしてもらいながら進めるのも良いでしょう。



コメント