
はじめに
カルバック・ライブラー情報量(Kullback–Leibler divergence、KLダイバージェンス)は、確率分布間の差異を定量的に評価するための指標です。
特に、ある確率分布から別の確率分布への変換がどれだけ情報を失うか、または追加するかを測定する際に使用されます。
この概念は、情報理論や統計学、機械学習など多くの分野で重要な役割を果たしています。
これらについて、理解が難しい場合は経験豊富な方とマンツーマンで学習していくのもオススメです。
カルバック・ライブラー情報量とは
カルバック・ライブラー情報量は、2つの確率分布\( P(x) \)と\( Q(x) \)があった場合に、\( P(x) \)を基準に\( Q(x) \)がどれだけ異なるかを測る指標です。数学的には次のように定義されます。
または、連続分布の場合は積分を使って表現されます。
ここで重要なのは、カルバック・ライブラー情報量は非対称的であり、つまり\( D_{\text{KL}}(P \parallel Q) \)と\( D_{\text{KL}}(Q \parallel P) \)は一般的に等しくないという点です。
この非対称性は、片方の分布を基準にしたときの情報量の増減が異なることを意味します。
カルバック・ライブラー情報量の具体例
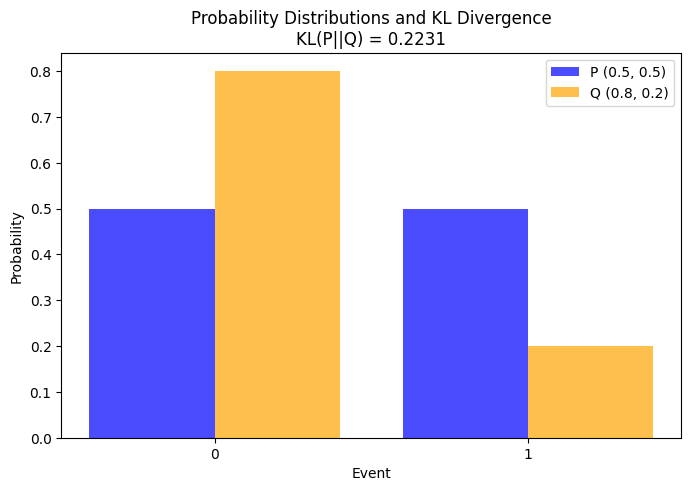
例えば、2つの異なる確率分布を考えます。一方が均等に0.5ずつ割り当てられた二項分布\( P(x) \)(コインの裏表が同じ確率で出る場合)、もう一方が0.8と0.2の確率で割り当てられた二項分布\( Q(x) \)(裏が80%、表が20%の偏ったコインの場合)です。
カルバック・ライブラー情報量の算出結果
この場合、カルバック・ライブラー情報量を計算すると、以下のようになります。
今回は簡単な2つの二項分布(青vsオレンジ)についてかるカルバック・ライブラー情報量を計算し、0.2231と出力されました。
基準分布を逆にした場合のカルバック・ライブラー情報量の算出結果
また、基準にした分布を逆にすることで数値が変わることも分かりました。
カルバック・ライブラー情報量の用途と注意点
カルバック・ライブラー情報量は、多くの機械学習アルゴリズムで使用されており、例えば、変分オートエンコーダー(VAE)では、潜在空間の分布と事前分布の差異を最小化するためにカルバック・ライブラー情報量が利用されています。
しかし、カルバック・ライブラー情報量を使用する際にはいくつかの注意点があります。まず、カルバック・ライブラー情報量は非対称であるため、評価する際にどちらの分布を基準にするかが重要です。また、カルバック・ライブラー情報量が無限大になってしまうことがあります。
まとめ
カルバック・ライブラー情報量は、確率分布間の差異を定量化する非常に有用なツールです。その非対称性と計算の特性を理解することで、さまざまな応用分野で効果的に使用することができます。特に、情報理論や機械学習においては、モデルの評価や改善において重要な役割を果たします。
このように、カルバック・ライブラー情報量はデータサイエンスの領域において欠かせない概念であり、理解を深めることで多くの実践的な課題に対応できるようになります。
統計に関する書籍や資格をまとめましたので参考ください。



コメント