
はじめに
データ分析や機械学習において、分類や予測のためによく使われるのが決定木分析(Decision Tree Analysis)です。
決定木分析は「もし〇〇なら△△」というルールを作り、データを分岐していくことで、最終的な答えを導きます。
この記事では、決定木分析がどんな時に使われるのかを分かりやすく説明し、実際の分岐例を示した上で、Pythonによる実装例も紹介します。
決定木分析は、様々な分析手法の基礎となっており、しっかりと理解することをオススメします。これらについて理解が難しい場合は、経験豊富な方とマンツーマンで学習していくのもオススメです。
決定木分析とは
決定木分析は、データを「質問」と「答え」を繰り返しながら分岐し、最終的な結論を出す手法です。
「ルールに従ってデータを分類する」ことが得意で、機械学習の中でも特に直感的に理解しやすいアルゴリズムです。
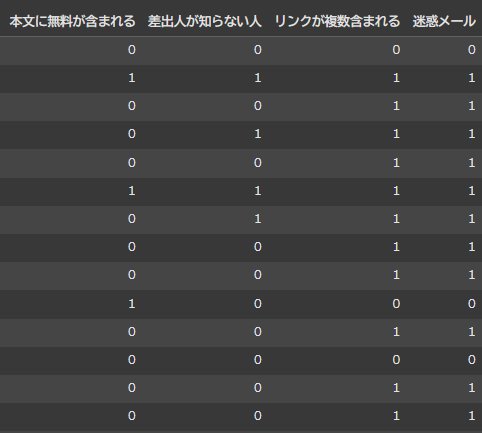
メールが迷惑メールかどうかを判断する際は下記のような決定木グラフとなります。データに基づいて、迷惑メールかどうかを木を分岐するような流れで分析をしていきます。

実際のデータは1か0のように数値に変えられてから、上記の解析がおこなれています。
- リンクが複数含まれる : 1/0
- 差出人が知らない人:1/0
- リンクが複数含まれる:1/0
- (Target) 迷惑メールか:1/0
決定木分析はどんな時に使われるか
決定木分析は、以下のような場面で使われます。
これに沿って、どのように分岐するのかもイメージしやすい例です。
① メールが迷惑メールかどうかを判断
たくさんのメールの中から、「迷惑メール」か「普通のメール」かを分類したいとします。
この場合、決定木は以下のように分岐します。
迷惑メール判定の決定木:
├── メールの本文にリンクが複数含まれる? → はい → 迷惑メール
│ → いいえ → 次の質問へ
├── 本文に「無料」が含まれる? → はい → 迷惑メール
│ → いいえ → 普通のメール② お客様が商品を買うかどうかを予測
「このお客様は商品を買うか?」を予測したい場合、次のような決定木が考えられます。
購入予測の決定木:
├── お客様の年齢が30歳以上? → はい → 次の質問へ
│ → いいえ → 購入しない
├── 過去にこの店で買い物をしたことがある? → はい → 購入する
│ → いいえ → 購入しない③ ある患者が病気にかかるリスクを判断
病院で「この患者さんは病気になる可能性が高いか?」を判断するとき、以下のような決定木が考えられます。
病気リスクの決定木:
├── 家族に同じ病気の人がいる? → はい → 次の質問へ
│ → いいえ → 低リスク
├── 1日にタバコを10本以上吸う? → はい → 高リスク
│ → いいえ → 中リスク分岐の方法
分岐はジニ不純度やエントロピーといった手法で計算され、最もらしい部分で分割されるように計算されます。
下記の記事でジニ不純度について説明しているので参考ください。

Pythonで決定木分析を実装してみる
それでは、実際にPythonを使って決定木を作ってみましょう。
ここでは、「花の種類を決定する決定木」を作成します。
(1) 必要なライブラリをインポート
Pythonで決定木を作成するには、scikit-learnというライブラリを使用します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_iris(2) データを準備
今回は、Iris(アヤメ)というデータセットを使います。
このデータには、3種類の花(Setosa, Versicolor, Virginica)の特徴が含まれています。
# データを読み込む
iris = load_iris()
X = iris.data # 花の特徴(がく片や花弁の長さなど)
y = iris.target # 花の種類(0: Setosa, 1: Versicolor, 2: Virginica)
# データを学習用とテスト用に分ける(8割を学習用、2割をテスト用)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)(3) 決定木を作成
学習用データを使って、決定木のモデルを作成します。
# 決定木のモデルを作成(木の深さを3に設定)
model = DecisionTreeClassifier(criterion="gini", max_depth=3, random_state=42)
# モデルを学習させる
model.fit(X_train, y_train)(4) 予測をしてみる
テストデータを使って、花の種類を予測します。
# 予測を実行
y_pred = model.predict(X_test)
# 予測結果を表示
print(y_pred)このようにどの花の種類かを予測することができます。

(5) 決定木を可視化してみる
決定木を図にして、どのようにデータが分岐しているかを見てみましょう。
# 決定木を可視化
plt.figure(figsize=(12, 8))
plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
この図を見ると、どの特徴を基準にして花の種類を分類しているかが視覚的に分かります。
まとめ
決定木分析は、データを「もし〇〇なら△△」というルールで分類し、シンプルかつ直感的に理解できる機械学習手法です。今回の例では、メールの特徴(「無料」という単語の有無」「差出人の認知度」「リンクの多さ」)などを基に、決定木の分析方法を紹介しました。
決定木は、迷惑メール判定以外にも、顧客分析・医療診断・需要予測など多くの分野で活躍し、この分析方法をベースとしたLightGBMはビジネスでも多く活用されています。自分のデータに適用し、適切な分析をしていただければと思います。
決定木分析を学ぶのにオススメの方法
書籍:機械学習図鑑
下記の書籍は初学者向けに様々な機械学習が視覚的に描かれています。決定木分析をはじめ、様々な分析について視覚的に理解していきたい方にはオススメです。

スクール:現役データサイエンティストに教えてもらう
決定木分析は様々な分析に使われていて、ビジネスでもよく用いられるため重要な分野になります。難しいと感じる場合は、相談しながら進められるスクールもオススメです。



コメント