
はじめに
クロスバリデーション(交差検証)は、モデルの性能をより正確に評価するためにデータセットを複数の分割に分けて訓練とテストを繰り返す方法です。
通常、データを訓練セットとテストセットに単純に分割する方法では、データの偏りや分割による偶然が評価に影響を与える可能性があります。クロスバリデーションを用いると、この影響を低減し、モデルの汎化性能(他のデータに対する適用性)を適切に評価できるようになります。python例も紹介するので、実際の業務でも生かしてみてください。
クロスバリデーションは、安定した精度検証の際に重要な技術となります。これらについて理解が難しい場合は、経験豊富な方とマンツーマンで学習していくのもオススメです。
ホールドアウト法
まず、クロスバリデーションの前にホールドアウト法について説明します。
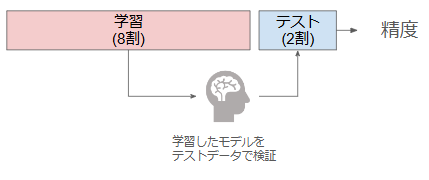
ホールドアウト法はシンプルな検証方法となります。データセットを「学習データ」と「テストデータ」に分割し、学習データで学習したモデルの結果をテストデータで評価するシンプルな手法です。
しかし、この方法ではデータの分割による評価結果のばらつきが発生しやすく、特にデータ量が少ない場合は偏った評価につながる可能性があります。
一般的に、下記のように学習データを8割、テストデータを2割として、テストデータを用いて精度を算出し検証します。
クロスバリデーション
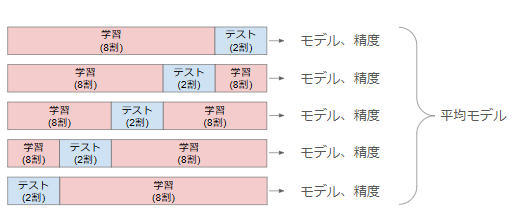
一方で、クロスバリデーションは、データを複数の分割に分けて何度も訓練と評価を繰り返す方法です。例えば、「k-分割クロスバリデーション」は、データをk個のグループに分割し、各グループを一度ずつテストデータとして使います。この方法により、全てのデータが一度はテストデータとして評価に使われるため、安定した評価が可能です。
一般的なk-分割クロスバリデーションの流れは以下の通りです。
- データセットをk個の分割に分けます。
- 各分割を順番にテストデータとして使用し、残りを訓練データとしてモデルを学習させます。
- k回の訓練と評価が終了したら、それぞれの評価結果の平均を取り、最終的なモデル性能として算出します。
下記に5個に分割した例を示します。
Pythonを用いたクロスバリデーションの実装例(LightGBM使用)
ここでは、オープンデータ「California Housing Dataset」を使い、LightGBMでの住宅価格予測を行います。この例では、5-分割クロスバリデーションを用いて、モデルの性能を安定して評価します。
まずはライブラリをインポートします。
# ライブラリのインポート
import lightgbm as lgb
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error次にデータを読み込んでいきます。
# カルフォルニア住宅データを読み込む
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)それではクロスバリデーションを実施していきます。KFoldを用いてクロスバリデーションを実施します。
今回は全てを特徴量として用います。
# クロスバリデーションの設定
kf = KFold(n_splits=5, shuffle=True, random_state=42)
rmse_scores = []
# クロスバリデーションのループ
for train_index, val_index in kf.split(X):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
# LightGBMデータセットの作成
train_data = lgb.Dataset(X_train, label=y_train)
val_data = lgb.Dataset(X_val, label=y_val, reference=train_data)
# モデルのパラメータ
params = {
"objective": "regression",
"metric": "rmse",
"boosting": "gbdt",
"verbosity": -1
}
# モデルの訓練
model = lgb.train(
params, train_data,
valid_sets=[val_data],
callbacks=[lgb.early_stopping(stopping_rounds=10)],
)
# 評価
y_pred = model.predict(X_val, num_iteration=model.best_iteration)
rmse = np.sqrt(mean_squared_error(y_val, y_pred))
rmse_scores.append(rmse)
# 平均RMSEの出力
print("クロスバリデーションでの平均MSE:", sum(rmse_scores) / len(rmse_scores))上記のコードを実行すると、5-分割クロスバリデーションでの平均RMSEが得られます。RMSEが低いほど、モデルの予測精度が高いことを意味します。また、クロスバリデーションにより、データ分割の影響を最小限に抑えた評価が可能となり、モデルの汎化性能が確認できます。
データによってはGroupKFold, StratifiedKFoldも検討
クロスバリデーションは、単にデータを分割するだけでなく、データの性質やタスクに合わせて適切な分割方法を選ぶことが重要です。特に、分類タスクやグループ単位での分割が必要な場合には、「StratifiedKFold」や「GroupKFold」といった特別なクロスバリデーションの方法が用いられます。
GroupKFold
GroupKFoldは、データに「グループ」の概念がある場合に使用されるクロスバリデーション方法です。例えば、同一ユーザーから複数のデータポイントがある場合や、同じ実験条件で測定されたデータなど、特定のグループ単位でデータがまとまっている場合に効果的です。
この方法では、同一グループが訓練セットとテストセットに分割されることがなくなり、グループ依存の影響を防ぎながら評価が可能です。
StratifiedKFold
StratifiedKFoldは、分類問題において、各分割でクラスの割合が均等になるようにデータを分けるクロスバリデーション方法です。特に、クラスの不均衡が大きいデータセットで有効であり、通常のk-foldではクラス比が偏る可能性を避けることができます。
まとめ
クロスバリデーションは、モデルの汎化性能を評価するために重要な手法です。ホールドアウト法に比べて、クロスバリデーションはデータの分割による評価のばらつきを減らし、より正確な評価が可能です。LightGBMのようなアルゴリズムと組み合わせることで、予測の安定性を高め、実際のデータに対する信頼性のあるモデルを構築することができます。
クロスバリデーションを学ぶのにオススメの方法
書籍:Kaggleで勝つデータ分析の技術
クロスバリデーションなど、機械学習の検証方法について体系的に学びたい方には以下の書籍がオススメです。クロスバリデーション以外にも多くの機械学習手法や精度向上手法が記載されているのでこちらの書籍で学習することをオススメします。

スクール:現役データサイエンティストに教えてもらう
機械学習を実施する際、精度の検証は必須の技術となります。ただ、どのようにやるのが正しいのかを判断するには適切なメンターなどがいた方が安心です。スクールなどに入り、アドバイスしてもらいながら進めるのも良いでしょう。



コメント