はじめに
現代のデジタル社会では、個人に最適化された情報や商品を提供する「レコメンドシステム」が不可欠です。その中でも、特に重要な技術が「協調フィルタリング(Collaborative Filtering)」です。
本記事では、協調フィルタリングの概要と、そのPythonでの実装方法について紹介します。
これらについて理解が難しい場合は、経験豊富な方とマンツーマンで学習していくのもオススメです。
協調フィルタリングとは
協調フィルタリングは、ユーザーとアイテムの相関関係を利用して、ユーザーが好みそうな商品や情報を推測する手法です。
この技術は、主に以下の2つのアプローチに分けられます。
- ユーザーベースの協調フィルタリング
似たような嗜好を持つユーザー同士の関係を利用してレコメンドを行います。例えば、AさんとBさんが共に複数の映画を高評価している場合、Aさんが未視聴のBさんお気に入りの映画をAさんにレコメンドすることができます。 - アイテムベースの協調フィルタリング
アイテム同士の関連性に基づいてレコメンドを行います。例えば、多くのユーザーがAのアイテムとBのアイテムを同時に高評価している場合、Aのアイテムを高評価したユーザーにBのアイテムをレコメンドすることができます。
これらの手法は、個々のユーザーが与えた評価データを用いて、他のユーザーやアイテムの評価を予測し、適切な推薦を行います。
協調フィルタリングのメリットと課題
協調フィルタリングは、ユーザーの明示的なフィードバック(例:商品評価)を活用できる点が大きな強みです。
また、アイテムのメタデータが不要で、ユーザー間の類似性のみでレコメンドが可能なため、汎用性が高いというメリットもあります。
しかし「コールドスタート問題」と呼ばれる、データが少ない場合に有効な推薦が難しくなる問題や、大規模なデータに対する計算コストの増大が挙げられます。
Pythonでの協調フィルタリング実装例(ユーザーベース)
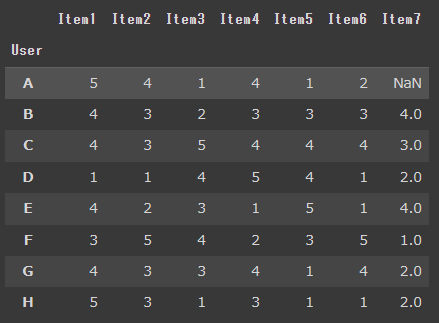
A~HさんがItemを使用してレビューを付けているとします。レビュー点数は1~5点とします。
その際、AさんがItem7を使用していなく、その点がどれくらいになるかを予測します。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# サンプルデータの作成
data = {
'User': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'],
'Item1': [5, 4, 4, 1, 4, 3, 4, 5],
'Item2': [4, 3, 3, 1, 2, 5, 3, 3],
'Item3': [1, 2, 5, 4, 3, 4, 3, 1],
'Item4': [4, 3, 4, 5, 1, 2, 4, 3],
'Item5': [1, 3, 4, 4, 5, 3, 1, 1],
'Item6': [2, 3, 4, 1, 1, 5, 4, 1],
'Item7': [np.nan, 4, 3, 2, 4, 1, 2, 2]
}
df = pd.DataFrame(data)
df.set_index('User', inplace=True)
display(df)
# Item7を除いたデータでユーザー間のコサイン類似度を計算
df_without_item7 = df.drop(columns=['Item7'])
user_similarity = cosine_similarity(df_without_item7)
user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)
display(user_similarity_df)
# Aさんに最も似ている3人を選択
top_3_similar_users = user_similarity_df.loc['A'].sort_values(ascending=False).index[1:4]
# Aさんが未評価のアイテムに対して、3人の近傍ユーザーの評価を基に予測を行う
target_user = 'A'
unrated_item = 'Item7'
# 他のユーザーの評価を取得
other_users_ratings = df.loc[top_3_similar_users, unrated_item]
# 類似度と他のユーザーの評価に基づいて加重平均を計算
weighted_sum = 0
sum_of_weights = 0
for other_user in top_3_similar_users:
if not pd.isna(other_users_ratings[other_user]): # 他のユーザーが評価しているか確認
similarity = user_similarity_df.loc[target_user, other_user]
weighted_sum += similarity * other_users_ratings[other_user]
sum_of_weights += abs(similarity)
# 評価予測
if sum_of_weights > 0:
predicted_rating = weighted_sum / sum_of_weights
else:
predicted_rating = 0 # 類似ユーザーがいない場合、予測は0にする
# 出力
print("Most similar 3 users:", top_3_similar_users.tolist())
print(f"\nPredicted Rating for User A on {unrated_item}: {predicted_rating:.2f}")
途中途中で出力結果を確認していきます。
協調フィルタリング ステップ1:今回用いているデータ
今回はそれぞれのユーザーが評価した値を分析データとします。AさんがItem7を使用していないため、レビュー評価点がありません。
このAさんがItem7の予測スコアが高いとすれば、リコメンドすることで企業は利益を向上できる可能性があります。
協調フィルタリング ステップ2:ユーザー間の類似度を算出する
その後、ユーザー間の類似度をコサイン類似度で出力します。
類似度指標はユークリッド距離や相関係数などありますが、場合に応じて使い分けるのがいいと思います。
見てみると、Aさんに似たユーザーは黄色線が引かれたB, G, Hさんになりました。
# Item7を除いたデータでユーザー間のコサイン類似度を計算
df_without_item7 = df.drop(columns=['Item7'])
user_similarity = cosine_similarity(df_without_item7)
user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)
display(user_similarity_df)
協調フィルタリング ステップ3:加重平均を用いた予測スコア
最終的に加重平均を用いることでAさんのItem7予測スコアを算出します。
この際は類似度が高いと判断されたユーザーのレビュー点数と類似度を用いて予測を行います。
# 類似度と他のユーザーの評価に基づいて加重平均を計算
weighted_sum = 0
sum_of_weights = 0
for other_user in top_3_similar_users:
if not pd.isna(other_users_ratings[other_user]): # 他のユーザーが評価しているか確認
similarity = user_similarity_df.loc[target_user, other_user]
weighted_sum += similarity * other_users_ratings[other_user]
sum_of_weights += abs(similarity)
Aさんに似ている上位三名のB, G, Hさんについて、加重平均を算出します。これがAさんのItem7に対するレビュースコアの予測点となります。
今回は2.65点となりましたが、もし高くスコアが出た場合は、何かしらレコメンデーションメールなどを行うのが有効となります。
まとめ
今回は例を用いてレコメンデーションスコアを出力しました。この点数が高い場合は、ビジネス的に何かしら対応するのが有効な手段となります。
出力されたスコアをどのように解釈し、どのように利用するかはシステムの設計次第となるので、ビジネスで効果が上がる手段を決めていきながら進めることが良いと思います。
協調フィルタリングにおススメの方法
書籍:推薦システム実践入門
こちらの書籍は推薦システムについて書かれた実装本で、実システムへの導入まで幅広く学ぶことができます。協調フィルタリングや推薦系のアルゴリズムに興味があれば購入することをおススメします。



コメント